(追記04/25 16:40:コメント欄に池田さんから米国の広告市場規模についての訂正をいただきましたので、このエントリのグーグルの広告モデル内のみでの成長性の部分については、大幅に書き直しました。)
某雑誌の方から、連休後に出る予定の特集に関連して、「グーグルについて定性的な分析をされる方はいらっしゃるんですが、財務的な観点から見てどうなのかコメントがほしいんですが」、という依頼があったので、ひさびさにGoogleの開示資料(10-K)を見てみました。
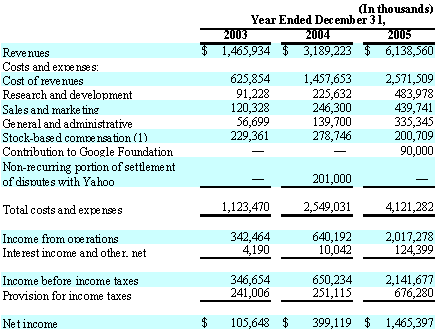
Googleの損益計算書は、下記のような感じになってます。
池田信夫さんのブログの記事「グーグルという神話」には、
(略)グーグルが日本でこうも崇拝されるのはなぜだろうか。先日も、田原総一朗氏に「グーグルのどこがすごいの?」と聞かれて、答に困った。検索エンジンとしての性能は、今ではヤフーやMSNなどもそう変わらない。広告というのは卸し売りのビジネスなので、市場規模は限られている。日本ではGDPの1%、米国では3%(追記:約1%に訂正)でほぼ一定している成熟産業である。グーグルの時価総額がインテルを抜いたというのは、かつてのライブドアと同じような「局所的バブル」である疑いが強い。
と書いてあります。
この記事を参考にさせていただいて、以下、財務的な観点からグーグルのビジネスについて考えてみます。
売上は今後も延びるのか?
前掲のP/Lのとおり、Googleは昨年度で6,138Mドル(1ドル115円[以下同様]として7,058億円)もの売上を既にあげています。
そして一昨年から昨年にかけての売上の伸びは92%。(つまり、ほぼ倍増。)
(追記)池田氏によると、「広告というのは(中略)日本ではGDPの1%」で、コメント欄でご紹介いただいた資料によると、米国では下表のとおり2005年度が広告費全体で143.3Bドル、インターネット広告はそのうち5.81%のシェアで、8,322.7Mドルのマーケットですが、当然のことながら、対前年比で13.3%と、メディア別の市場の中では最大の伸びを示しています。
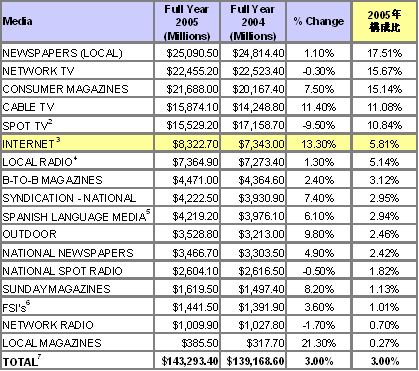
広告市場全体の対GDP比は、米国のGDP 11兆7,343億ドル(外務省HPによる。名目2004年。)に対しては、やはり1%程度。グーグルの売上6,138Mドルは当然海外売上げも含まれていますが、米国インターネット市場に対する単純な割合を取ると、約7割にもなります。
今後、インターネット広告市場が当面は加速を続け、対前年比20%→25%→30%→35%程度で成長すると仮定すると、2009年のマーケットは21,908Mドルで、広告市場全体のサイズは横ばいとすると、インターネット広告が約15%を占めるということになります。
(それほど非現実的な仮定ではないかと。)
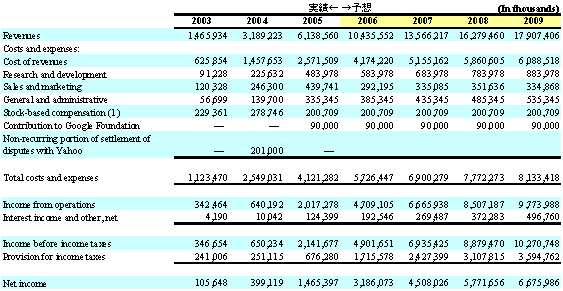
Googleの成長率92%が、今後、85%→75%→65%→55%70%→30%→20%→10%(広告費のみ)と鈍化していくとすると、4年後の2009年の売上は50,826M 17,907Mドルで、上記の米国広告市場比で約12.5%(当然、全世界市場比でいくと、もっと低い)になります。(/追記)
基本的にネット広告は既存の広告メディアより効率もよく、また顧客の行動も見えやすい等のメリットがあるので、広告費全体は横ばいでも、今後もネット広告のシェアが増えていくのは間違いないところでしょう。そのネット広告の中でも、グーグルのシェアがダントツになる可能性は高いので、4年後に米国市場比で12.5%(当然、全世界市場比でいくと、もっと低い)をGoogleが取るというのは、これもそれほど非現実的なシナリオではないと思います。
従来型広告代理店よりもはるかに高い利益率
Googleは、上記のP/Lのとおり、売上の約24%が純利益になるという高収益率のビジネスです。(売上高税引前利益率だと34.9%。)
電通さんの2005年3月期の売上1.9兆円に対して純利益が275億円(利益率約1.4%)というイメージで考えると、「広告はそんなにおいしいビジネスじゃなさそう」と思えるかも知れませんが、税引後で売上の4分の1もが手元に残るというなら話は違ってきます。
では、この利益率は、今後どう変化していくでしょうか。
変動費らしき科目
「Cost of revenues」と「Sales and marketing」の売上比を見てみると、3期ともだいたい合計で50%前後。(追記)「Sales and marketing」の方は固定費的要素もあると考えて、売上高比昨年7.2%のところ、7.0%→6.5%→6.0%→5.5%と下がっていくと仮定します。(/追記)
研究開発費と販管費
一方、「Research and development」とか「General and administrative」というのは、基本的には固定費でしょう。Googleは研究開発に力を入れてますので、研究開発費は極力増やそうとするでしょうけど、(追記)昨年555億円の研究費を、売上に比例して増やしていくのはそれなりに大変そうなので、毎年100Mドルづつ増加させる想定とします。
(現実には、Googleははるかに大きな金額を投資するでしょうけど、売上は広告モデルの域を出ないと仮定しているので、そのための研究開発費は2009年で884Mドルもあればいい、と想定しています。)(/追記)
資金運用による収益
また、B/Sを見て頂くと、Googleは昨年末で「Cash等」+「Marketable securities」合計で9,000億円(!) ほどのお金を貯め込んでます。上述のようなペースで利益があがっていくと、(新たなファイナンスをしなくても、)4年後には3兆円を超えるキャッシュを持つことになります。
昨年末と一昨年末のキャッシュの平均残高に対する「Interest income and other, net」の割合(利回り)は約1.2%程度。下記のシミュレーションでは、こうしたキャッシュの平残の2%をそうした営業外収益として見込んでいますが、これはハーバードの2兆円超のファンドが10%超で運用されていることを考えるとちょっと低めな想定かも知れません。(つまり、全部キャッシュでため込んで低利で運用することを想定していて、「ROE20%の事業を買収する」といったことは前提条件に入れてないわけです。当然、キャッシュを投資せずに4年後に3兆円抱えているという戦略は、実際にはありえません。)
数年後にトヨタの利益を超える?
それでも、一所懸命コストの使い途を考えて、4年後の利益率が現状からやや上がる程度としても、2009年の純利益は10Bドル(1.15兆円)
6,675Mドル(約7600億円)となりますので、日本企業で純利益第二位のNTTドコモを超えることになります。(1位は、製造業利益世界一のトヨタ自動車1.17兆円。)
また、上記は、基本的にはグーグルのビジネスモデルが広告モデルの域を出ないことを仮定していたシミュレーションなわけですが、実際にはグーグルは新しいrevenue streamを作り出す可能性は高い。グーグルは、「広告業」を目指したいわけではなくて、大量の情報をハンドルするエージェントになりたいわけなので、「分母」を広告費に限定するつもりもないのではないかと思います。
経済学的には「利益率の高い企業が小さな市場で大もうけ」というのはトリビアルな話かも知れませんが、財務的に見れば、グーグルはすでに世界の企業の中でもかなり「すごい」企業だと言っていいんじゃないでしょうか。
池田さんが説明に苦労されたという田原総一朗氏にも、「数年前にスタンフォードの若者2人が作った企業が、このままいくとあと数年でトヨタの利益を抜きそうきかねない勢いなんですよ」と説明すれば、素直に「そりゃすごいね」と感心していただけるのではないかと思います。
以上をまとめたのが、以下のような予想P/L。
(基本的に、非常に荒っぽいシミュレーションですので、ご注意ください。)
グーグルは「バブル」か?
Google(GOOG)の本日のMarket Capは129.92Bドル(約15兆円)で、確かにインテル(INTC)の112.13Bドルを抜いてます。
ただし、インテルの売上は去年38,826Mドル、net income は8,664Mドルのほどあるものの、グーグルと違って売上の伸びはここ数年10%台に留まっており、完全に安定成長モード。
グーグルが成長を続けて前述のように世界の広告市場のちょっとした割合を獲得するとしたら、4年後にPER10倍20倍台まで落ち込むとしても、10兆円台の時価総額は十分説明がつくことになります。
今後の売上がホントに上記のように伸びるかどうかは、あくまで将来の想定を含みますので、そういう意味ではバブルの可能性はゼロではないですが、現時点ですでにちゃんと7,000億円以上もの売上を計上しているわけですから、ライブドアのように、買収した企業の売上を足しあわせて数字を作っていた企業と違って、大企業としての「実態」がすでにあるという点は、かなり違うのではないかと思います。
ご注意:
本分析は、上述の通り、基本的には現状の勢いで今後も数年成長するという仮定に基づいてますので、強力なコンペティターが現れるなど今後何が起こるかわかりませんし、今後のGoogleの儲けを私が保証するもんではありませんので、悪しからず。
(ご参考まで。)
[PR]
メールマガジン週刊isologue(毎週月曜日発行840円/月):
「note」でのお申し込みはこちらから。










